TP KNN : Classification des survivants du Titanic#
Pour programmer, vous pouvez soit utiliser IDLE, soit utiliser IDLE ! Aujourd’hui, nous nous mettons dans les conditions les plus rudimentaires que l’on pourrait vous proposer. Un interpreteur sans rien et bonne chance !

On souhaite prédire si un passager du Titanic a survécu ou non à l’accident, en utilisant l’algorithme des plus proches voisins. On pourra s’inspirer de l’exemple du cours sur la classification de fleurs.
Voici les informations sur chaque passager :
Survived: 0 = Non, 1 = OuiPclass: Classe de ticket (1 = 1ère classe, 2 = 2ème, 3 = 3ème)Sex: Sexe du passager (maleoufemale)Age: Âge du passager (en années)Fare: Tarif du ticket (en dollars)
Chargement des données avec Pandas#
Pandas est un module Python qui permet de manipuler des données sous forme de tableau appelé DataFrame (qui ressemble à un peu à une table SQL).
Pour charger les données :
Télécharger les données (clic droit ici puis enregistrer sous).
Déplacer les données dans votre dossier courant.
Exécuter le code ci-dessous, en modifiant titanic.csv si vous avez utilisé un autre nom de fichier.
import pandas as pd
df = pd.read_csv('titanic.csv') # df est un DataFrame
df.head() # pour afficher les 5 premières lignes
| Survived | Pclass | Sex | Age | Fare | |
|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 7.2500 |
| 1 | 1 | 1 | female | 38.0 | 71.2833 |
| 2 | 1 | 3 | female | 26.0 | 7.9250 |
| 3 | 1 | 1 | female | 35.0 | 53.1000 |
| 4 | 0 | 3 | male | 35.0 | 8.0500 |
Ainsi df est un tableau contient 5 colonnes (Survived, Pclass, Sex, Age, Fare) et chaque ligne correspondant à un passager du Titanic. On peut obtenir le nombres de lignes avec len(df) :
len(df)
891
Chaque ligne est identifiée par un index (= nom de la ligne), ici \(0, 1, 2, ...\). On peut accéder à la ligne d’indice \(i\) avec df.loc[i] :
df.loc[0]
Survived 0
Pclass 3
Sex male
Age 22.0
Fare 7.25
Name: 0, dtype: object
df.loc[i] donne en fait une Series, qui peut être vu comme un tableau (à une dimension).
On peut récupérer une colonne (également sous forme de series), par exemple Age, avec df["Age"] :
df["Age"]
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
...
886 27.0
887 19.0
888 28.0
889 26.0
890 32.0
Name: Age, Length: 891, dtype: float64
On peut combiner ces deux méthodes pour récupérer une valeur précise, par exemple l’âge du 3ème passager :
df.loc[2, "Age"]
np.float64(26.0)
On peut aussi modifier une valeur avec, par exemple, df.loc[2, "Age"] = ....
On peut parcourir les indices d’un dataframe avec df.index. Par exemple, pour trouver le passager le plus vieux :
maxi_age = 0
for i in df.index:
if df.loc[i, "Age"] > maxi_age:
maxi_age = df.loc[i, "Age"]
maxi_age
np.float64(80.0)
Remarque : avec Pandas, il faut normalement utiliser au maximum des opérations vectorielles pour que le processeur puisse effectuer les calculs en parallèle. Cependant, comme l’utilisation de Pandas n’est pas au programme, nous allons nous limiter à une approche élémentaire.
Statistiques#
Question
Écrire une fonction moyenne(df, c) qui renvoie la moyenne des valeurs sur la colonne c du dataframe df. Quelle est l’âge moyen des passagers du Titanic ? Le prix moyen du ticket ?
Solution
Show code cell content
def moyenne(df, col):
m = 0
for i in df.index:
m += df.loc[i, col]
return m / len(df)
print("Âge moyen :", moyenne(df, "Age"))
print("Prix moyen du billet :", moyenne(df, "Fare"))
Âge moyen : 29.36158249158249
Prix moyen du billet : 32.2042079685746
Question
Écrire une fonction ecart_type(df, c) qui renvoie l’écart-type des valeurs de la colonne c du dataframe df. On rappelle que l’écart-type d’une série de valeurs \(x_1, \ldots, x_n\) est donné par :
où \(\bar{x}\) est la moyenne des valeurs \(x_1, ..., x_n\).
Remarque : On évitera de calculer plusieurs fois la même moyenne.
Solution
Show code cell content
def ecart_type(df, col):
m = moyenne(df, col)
s = 0
for i in df.index:
s += (df.loc[i, col] - m)**2
return (s / len(df))**0.5
ecart_type(df, "Age")
np.float64(13.01238827279366)
Question
Afficher le pourcentage de survivants parmi :
les personnes de sexe masculin
les personnes de sexe feminin
les passagers de 1ère classe
les passagers de 3ème classe
Solution
Show code cell content
def survivants(col, val):
n_survivants = 0
n = 0
for i in df.index:
if df.loc[i, col] == val:
n_survivants += df.loc[i, "Survived"]
n += 1
return n_survivants/n
for c, v in [("Sex", "male"), ("Sex", "female"), ("Pclass", 1), ("Pclass", 3)]:
print("Taux de survie pour", c, "=", v, ":", survivants(c, v))
Taux de survie pour Sex = male : 0.18890814558058924
Taux de survie pour Sex = female : 0.7420382165605095
Taux de survie pour Pclass = 1 : 0.6296296296296297
Taux de survie pour Pclass = 3 : 0.24236252545824846
Variables catégorielles#
Nous souhaitons modéliser chaque passager par un vecteur de \(\mathbb{R}^4\) (car il y a \(4\) informations pour chaque passager : âge, sexe, classe et prix du ticket). Cependant, le sexe est une variable catégorielle qu’il faut transformer en variable numérique :
df["Sex"] = df["Sex"].map({"male": 0, "female": 1}) # remplace male par 0 et female par 1
df.head()
| Survived | Pclass | Sex | Age | Fare | |
|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 22.0 | 7.2500 |
| 1 | 1 | 1 | 1 | 38.0 | 71.2833 |
| 2 | 1 | 3 | 1 | 26.0 | 7.9250 |
| 3 | 1 | 1 | 1 | 35.0 | 53.1000 |
| 4 | 0 | 3 | 0 | 35.0 | 8.0500 |
Standardisation#
On remarque que les attributs sont sur des échelles très différentes (par exemple, l’âge est entre 0 et 80, alors que la classe du billet est entre 1 et 3).
Les différences d’âge contribuent alors beaucoup plus dans les calculs de distance, ce qui ferait que l’âge aurait un poids plus important que la classe du billet pour la prédiction.
Pour éviter cela, on va standardiser les données, c’est-à-dire les transformer de manière à ce que chaque attribut ait une moyenne nulle et un écart-type égal à 1.
Si un attribut \(x\) a une moyenne \(\bar{x}\) et un écart-type \(\sigma\), on peut le standardiser en le remplaçant par :
Question
Écrire une fonction standardiser(df, c) qui standardise la colonne c du dataframe df. L’utiliser pour standardiser les colonnes Age, Fare, Pclass et Sex. On rappelle qu’on peut modifier l’élément sur la ligne i et la colonne c avec df.loc[i, c] = ....
Solution
Show code cell content
def standardiser(df, col):
m = moyenne(df, col)
s = ecart_type(df, col)
for i in df.index:
df.loc[i, col] = (df.loc[i, col] - m) / s
for c in ["Age", "Fare", "Pclass", "Sex"]:
standardiser(df, c)
df.head()
/tmp/ipykernel_55091/583169686.py:5: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value '0.8273772438659676' has dtype incompatible with int64, please explicitly cast to a compatible dtype first.
df.loc[i, col] = (df.loc[i, col] - m) / s
/tmp/ipykernel_55091/583169686.py:5: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value '-0.7376951317802897' has dtype incompatible with int64, please explicitly cast to a compatible dtype first.
df.loc[i, col] = (df.loc[i, col] - m) / s
| Survived | Pclass | Sex | Age | Fare | |
|---|---|---|---|---|---|
| 0 | 0 | 0.827377 | -0.737695 | -0.565736 | -0.502445 |
| 1 | 1 | -1.566107 | 1.355574 | 0.663861 | 0.786845 |
| 2 | 1 | 0.827377 | 1.355574 | -0.258337 | -0.488854 |
| 3 | 1 | -1.566107 | 1.355574 | 0.433312 | 0.420730 |
| 4 | 0 | 0.827377 | -0.737695 | 0.433312 | -0.486337 |
Distance#
Pour la question suivante, on rappelle comment accéder aux attributs d’une donnée :
p = df.loc[0] # 1er passager
p["Age"], p["Fare"], p["Pclass"], p["Sex"] # attributs de p
(np.float64(-0.565736461074875),
np.float64(-0.5024451714361915),
np.float64(0.8273772438659676),
np.float64(-0.7376951317802897))
Question
Écrire une fonction distance(p1, p2) qui calcule la distance euclidienne entre les passagers p1 et p2. On prendra en compte tous les attributs sauf Survived.
Solution
Show code cell content
def distance(p1, p2):
d = 0
for c in ["Pclass", "Sex", "Age", "Fare"]:
d += (p1[c] - p2[c])**2
return d**0.5
distance(df.loc[0], df.loc[1]) # distance entre les deux premiers passagers
np.float64(3.644820996221396)
Séparation des données#
On sépare les données en deux : une partie train utilisée pour la prédiction, et une partie test utilisée pour évaluer la qualité de la prédiction :
train = df.sample(frac=0.9,random_state=0)
test = df.drop(train.index)
print("nombre de données dans train :", len(train))
print("nombre de données dans test :", len(test))
nombre de données dans train : 802
nombre de données dans test : 89
Algorithmes des plus proches voisins#
Question
Écrire une fonction voisins(x, k) qui renvoie les indices des \(k\) plus proches voisins de x dans train.
Solution
Show code cell content
def voisins(x, k):
indices = sorted(train.index, key=lambda i: distance(x, train.loc[i]))
return indices[:k]
voisins(test.iloc[0], 5)
[446, 651, 546, 427, 389]
Question
Écrire une fonction plus_frequent(L) qui renvoie l’élément le plus fréquent d’une liste L.
Solution
Show code cell content
def plus_frequent(L): # renvoie la classe qui apparaît le plus souvent dans L
compte = {}
for e in L:
compte[e] = compte.get(e, 0) + 1
return max(compte, key=compte.get)
plus_frequent([2, 1, 5, 1, 2, 5, 5])
5
Question
Écrire une fonction knn(x, k) qui renvoie la prédiction de survie de x en utilisant l’algorithme des \(k\) plus proches voisins.
Solution
Show code cell content
def knn(x, k):
return plus_frequent([train.loc[i, "Survived"] for i in voisins(x, k)])
knn(test.iloc[0], 5)
np.int64(1)
Analyse des résultats#
Question
Écrire une fonction precision(k) qui renvoie la précision de l’algorithme des \(k\) plus proches voisins en utilisant k voisins.
Remarque : cela peut prendre quelques secondes.
Solution
Show code cell content
def precision(k):
n = 0
for i in test.index:
if knn(test.loc[i], k) == test.loc[i, "Survived"]:
n += 1
return n / len(test)
precision(3)
0.8314606741573034
Question
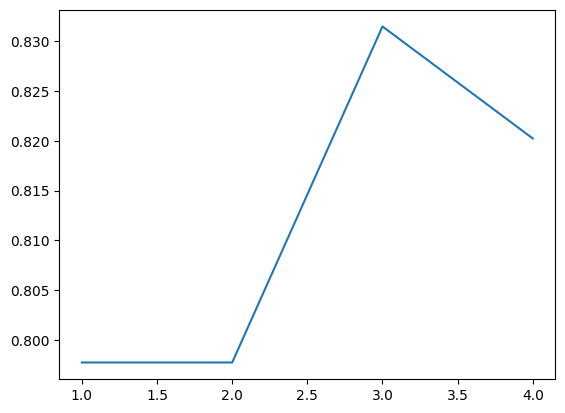
Écrire une fonction plot_precision(kmax) qui trace la précision pour \(k\) variant de \(1\) à kmax. Quelle est la meilleure précision obtenue pour k entre 1 et 5 (cela prend environ 1 minute) ? Quelle est le nombre de voisins optimal ?
Solution
Show code cell content
def plot_precision(kmax):
import matplotlib.pyplot as plt
R = range(1, kmax)
plt.plot(R, [precision(k) for k in R])
plt.show()
plot_precision(5)
Kaggle#
Kaggle est un site proposant des compétitions de sciences des données. Ce TP provient d’une compétition Kaggle : Titanic: Machine Learning from Disaster.
Avec KNN, j’obtiens un score de \(\approx 0.763\)… Ce qui n’est pas terrible car l’exemple de submission basée uniquement sur le sexe des passagers donne un score de \(\approx 0.765\).