---
jupytext:
text_representation:
extension: .md
format_name: myst
format_version: 0.13
jupytext_version: 1.16.4
kernelspec:
display_name: Python 3 (ipykernel)
language: python
name: python3
---
# TP: Dictionnaires
Pour programmer, vous pouvez soit utiliser Pyzo, soit [Basthon](https://notebook.basthon.fr/?from=https://raw.githubusercontent.com/tcanta/itc2a/master/eleve/tp_structures-eleves.ipynb).
Commandes Basthon :
- Ctrl + Entrée : exécuter la cellule
- Shift + Entrée : exécuter la cellule puis passer à la suivante
- Entrée : passer en mode édition
- Échap : sortir du mode édition
Les commandes suivantes sont valables uniquement hors du mode édition :
- A : créer une nouvelle cellule (en haut)
- B : créer une nouvelle cellule (en bas)
- D D : supprimer la cellule
+++
## Internationalisation
+++
:::{admonition} Exercice 1
:class: note
1. Définir un dictionnaire `fr_to_en` contenant chaque jour de la semaine (en français) avec sa traduction en anglais.
2. Vérifier que `fr_to_en["lundi"]` contient `"monday"`.
3. Ajouter les mois avec leurs traductions.
:::
**Solution**
```{code-cell} ipython3
:tags: ["hide-cell"]
# 1.
fr_to_en = {"lundi": "Monday", "mardi": "Tuesday", "mercredi": "Wednesday", "jeudi": "Thursday", "vendredi": "Friday", "samedi": "Saturday", "dimanche": "Sunday"}
# 2.
print(fr_to_en["lundi"])
# 3. On peut utiliser une boucle for pour simplifier
for m1, m2 in [("janvier", "January"), ("février", "February"), ("mars", "March"), ("avril", "April"), ("mai", "May"), ("juin", "June"), ("juillet", "July"), ("août", "August"), ("septembre", "September"), ("octobre", "October"), ("novembre", "November"), ("décembre", "December")]:
fr_to_en[m1] = m2
```
---
+++
## Élément majoritaire
+++
:::{admonition} Exercice 2
:class: note
Écrire une fonction `majoritaire(L)` renvoyant l'élément apparaissant le plus souvent dans la liste `L`, sans utiliser de dictionnaire. Quelle est sa complexité ?
:::
**Solution**
```{code-cell} ipython3
:tags: ["hide-cell"]
# en utilisant count :
def majoritaire(L):
m = L[0] # va contenir l'élément majoritaire
for e in L:
if L.count(e) > L.count(m):
m = e
return m
# sans utiliser count :
def majoritaire(L):
m, n = None, 0 # va contenir l'élément majoritaire et son nombre d'occurences
for e in L:
n_e = 0 # nombre d'occurences de e
for f in L:
if f == e:
n_e += 1
if n_e > n:
m = e
n = n_e
return m
# dans les deux cas, la complexité est O(n^2), où n est la longueur de la liste L
```
---
:::{admonition} Exercice 3
:class: note
Écrire une fonction `majoritaire2(L)` renvoyant l'élément apparaissant le plus souvent dans la liste `L`, en utilisant un dictionnaire pour avoir une meilleure complexité que la fonction précédente.
:::
**Solution**
```{code-cell} ipython3
:tags: ["hide-cell"]
# Fonction écrite en cours. La complexité est O(n), où n est la longueur de la liste L.
def majoritaire2(L):
d = {}
for e in L:
if e in d:
d[e] += 1
else:
d[e] = 1
m = L[0]
for e in d:
if d[e] > d[m]:
m = e
return m
```
```{code-cell} ipython3
majoritaire2([9, 1, 9, 0, 1, 1, 0])
```
---
+++
## Anagramme
+++
On rappelle qu'on peut parcourir les lettres d'une chaîne de caractères avec une boucle for :
```{code-cell} ipython3
s = "lamartin"
for c in s: # en parcourant directement les caractères
print(c)
for i in range(len(s)): # en parcourant les indices
print(s[i])
```
:::{admonition} Exercice 4
:class: note
Écrire une fonction `anagramme(m1, m2)` qui teste si deux mots (des chaînes de caractères) sont des anagrammes, c'est-à-dire s'ils contiennent les mêmes lettres (avec le même nombre d'occurence de chaque lettre).
Cette fonction doit être en O($n_1 + n_2$), où $n_1$, $n_2$ sont les tailles de `m1`, `m2`.
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
def anagramme(m1, m2):
d1, d2 = {}, {}
for c in m1: # O(n1)
if c in d1:
d1[c] += 1
else:
d1[c] = 1
for c in m2: # O(n1)
if c in d2:
d2[c] += 1
else:
d2[c] = 1
return d1 == d2 # O(n1)
```
```{code-cell} ipython3
print(anagramme("ordre", "dorer"))
print(anagramme("ordre", "oreo"))
```
---
+++
## Trie (arbre préfixe)
+++
### Arbres enracinés
Un **arbre** est un graphe ayant deux propriétés supplémentaires :
- **Connexe** : il existe un chemin entre deux sommets quelconques
- **Acyclique** : il ne contient pas de cycle
On considère souvent des **arbres enracinés**, c'est-à-dire ayant un sommet particulier appelé la **racine**, qu'on représente en haut de l'arbre :
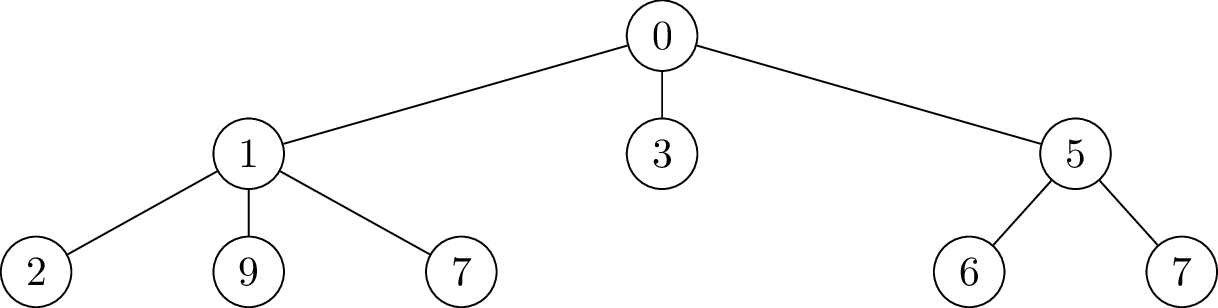
Exemple d'arbre, ayant pour racine 0
Chaque sommet différent de la racine possède un **père**, qui est le sommet juste au dessus. Sur l'exemple, 0 est le père de 1, 1 est le père de 7...
Si p est le père de v, on dit aussi que v est un **fils** de p. Chaque sommet a au plus un père, mais peut avoir un nombre quelconque de fils.
---
### Trie
Un **trie** sert à stocker un ensemble de mots sous forme d'arbre. Chaque arête est etiquetée par une lettre et les mots appartenant au trie sont ceux obtenus le long d'un chemin de la racine à une arête étiquetée par $.
Par exemple, l'arbre suivant contient les mots cap, copie, copier, copies, cor, corde, corne, correct, correcte :
 **Remarque** : les tries sont utilisés pour la complétion automatique (proposition de complétion d'un mot en cours d'écriture, par exemple sur téléphone), pour la correction orthographique...
Pour stocker un trie, on utilisera un dictionnaire où chaque clé est l'étiquette d'une arête sortant de la racine et la valeur est le dictionnaire correspondant au fils. Une feuille (sommet sans fils) est représentée par le dictionnaire vide.
Par exemple, le trie contenant l'ensemble de mots $\{$ car, cat, cd, ok $\}$ est représenté par :
```{code-cell} ipython3
trie_ex = {
"c" : {
"a" : {
"r" : { "$" : {} },
"t" : { "$" : {} }
},
"d" : { "$" : {} }
},
"o" : {
"k" : { "$" : {} }
}
}
trie_ex
```
:::{admonition} Exercice 5
:class: note
1. Dessiner le trie contenant les mots art, axe, set.
2. Définir ce trie sous forme d'un dictionnaire.
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
trie = {
"a": {
"r": {
"t": { "$" : {} },
},
"x": {
"e": { "$" : {} },
},
},
"s": {
"e": {
"t": { "$" : {} },
},
},
}
```
---
:::{admonition} Exercice 6
:class: note
Écrire une fonction `trie_size(trie)` pour afficher le nombre de mots appartenant à un trie. Pour cela, on parcourt récursivement le trie en comptant le nombre de $.
:::
```python
def trie_size(trie):
n = 0 # compte le nombre de $
for k in trie:
...
return n
```
```{code-cell} ipython3
:tags: ["hide-cell"]
def trie_size(trie):
n = 0
for k in trie:
if k == '$':
return 1
else:
n += trie_size(trie[k])
return n
```
```{code-cell} ipython3
trie_size(trie_ex)
```
---
:::{admonition} Exercice 7
:class: note
Écrire une fonction `trie_add(trie, m)` pour ajouter un mot `m` dans un trie. On pourra compléter le code ci-dessous.
:::
```python
def trie_add(trie, m):
for c in m: # parcours des lettres c de m
if ...: # s'il n'y a pas d'arête sortante de trie étiquetée par c
... # créer une nouvelle association (c, dictionnaire vide)
trie = trie[c] # descendre dans l'arbre suivant la lettre c
... # ajouter un '$' à la fin
```
```{code-cell} ipython3
:tags: ["hide-cell"]
def trie_add(trie, m):
for c in m:
if c not in trie:
trie[c] = dict()
trie = trie[c]
trie['$'] = dict()
```
```{code-cell} ipython3
trie = {}
trie_add(trie, "arbre")
trie_add(trie, "arete")
trie
```
---
:::{admonition} Exercice 8
:class: note
Écrire une fonction `trie_print(trie)` pour afficher les mots `m` appartenant à un trie. Vérifier avec l'exemple précédent.
On pourra utiliser une fonction auxiliaire récursive `aux(t, m)` qui s'appelle récursivement sur chaque noeud `t` du trie, en conservant les lettres déjà parcourues dans la chaîne de caractères `m`.
:::
```python
def trie_print(trie):
def aux(t, m):
...
aux(trie, "")
```
```{code-cell} ipython3
:tags: ["hide-cell"]
def trie_print(trie):
def aux(t, m):
for k in t:
if k == '$':
print(m)
else:
aux(t[k], m + k)
aux(trie, "")
```
```{code-cell} ipython3
trie_print(trie_ex)
```
---
:::{admonition} Exercice 9
:class: note
Écrire une fonction `trie_has(trie, m)` pour tester si `m` appartient à un trie.
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
def trie_has(trie, mot):
def aux(t, m, i): # t est le sous-arbre, m est le mot recherché, i est l'indice de la lettre courante
if i == len(m):
return '$' in t
if m[i] not in t:
return False
return aux(t[m[i]], m, i + 1)
return aux(trie, mot, 0)
```
```{code-cell} ipython3
print(trie_has(trie_ex, "carte"))
print(trie_has(trie_ex, "car"))
```
---
**Compléments :**
## Fonctions de hachage
De manière informelle, on dit qu'une fonction $h : X \longrightarrow Y$ est une **fonction de hachage** si $X$ est un ensemble de grande taille (généralement infini) et $Y$ est un ensemble fini (souvent un ensemble d'entiers).
L'intérêt d'une fonction de hachage est de transformer un élément "complexe" $x \in X$ (par exemple, une image, un film...) en une empreinte $h(x)$ qui soit plus simple à manipuler et qui utilise moins d'espace mémoire.
Quelques propriétés souhaitables, selon le contexte, sur une fonction de hachage :
- Facilement calculable : pouvoir calculer $h(x)$ en O(1), par exemple.
- Difficile à inverser : étant donné un $y$, il doit être impossible en pratique (c'est-à-dire prendre un temps extrêment long - typiquement une complexité exponentielle) de trouver un $x$ tel que $h(x) = y$.
- Résistance aux collisions : il doit être impossible en pratique de trouver $x, x' \in X$ tels que $h(x) = h(x')$.
Voici quelques applications possibles des fonctions de hachage :
- Table de hachage : c'est une implémentation possible de dictionnaire (voir cours).
- Stockage de mot de passe : au lieu de mémoriser un mot de passe en clair sur un ordinateur ou une base de donnée (qui peut être compromis), on conserve son empreinte par une fonction de hachage.
- Signature numérique : ajout d'une empreinte à un email permettant de garantir l'identité de son expéditeur.
- Checksum : vérifier qu'un fichier a été téléchargé sans erreur, en comparant son empreinte à l'empreinte originale.
### Checksum
Une des applications des fonctions de hachage consiste à vérifier l'intégrité d'un fichier après l'avoir téléchargé (pour détecter d'éventuelles erreurs de transmission). Pour cela, on calcule une empreinte (*checksum*) du fichier téléchargé que l'on compare avec l'empreinte du fichier original.
Dans la suite, nous implémentons un algorithme de checksum très simple (mot de parité) sur une chaîne de caractères.
Dans la suite, on utilisera `ord(c)` qui renvoie le code Unicode d'un caractère `c`.
:::{admonition} Exercice 10
:class: note
Quel est le code Unicode de `a` ? de `z` ?
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
ord('a') # 97
ord('z') # 122
```
---
:::{admonition} Exercice 11
:class: note
Écrire une fonction `code(s)` renvoyant une liste `L` telle que `L[i]` soit le code Unicode de `s[i]`.
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
def code(s):
L = []
for c in s:
L.append(ord(c))
return L
```
```{code-cell} ipython3
code("lamartin")
```
Si $a$ est un entier, on note $a_i$ le $i$ème bit de $a$ en base $2$. Le XOR de deux entiers $x$ et $y$ est un entier $z$ tel que $z_i = 1$ si et seulement si $x_i = 1$ ou $y_i = 1$, mais pas les deux. Par exemple, le XOR de $9 = 1001_2$ et $5 = 0101_2$ est $12 = 1100_2$.
En Python, le XOR est obtenu par `x^y`.
:::{admonition} Exercice 12
:class: note
Sans ordinateur, convertir $11$ et $6$ en base $2$ puis calculer leur XOR. Vérifier ensuite avec Python.
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
def checksum(s):
from functools import reduce
return reduce(lambda x, y: x^y, map(ord, s))
# Est-ce le code le plus clair ? Pas quand on utilise pas les lambda expressions régulièrement...
```
```{code-cell} ipython3
checksum("martin")
```
---
### Recherche de collisions
Une des propriétés désirable sur une fonction de hachage est d'être résistante aux collisions : il doit être très difficile en pratique de trouver $x, x' \in X$ tels que $h(x) = h(x')$. Sinon, il serait possible pour un attaquant d'envoyer un message en lui attribuant une signature d'une autre personne, par exemple.
MD5 est une fonction de hachage célèbre qui n'est plus considérée comme sûre : des collisions MD5 ont notamment été utilisées [par un malware qui a touché l'Iran](https://en.wikipedia.org/wiki/Flame_(malware)).
Dans la suite, nous cherchons des collisions partielles pour MD5.
Voici un exemple d'utilisation de MD5 :
```{code-cell} ipython3
import hashlib
def md5(s):
return hashlib.md5(s.encode("utf-8")).hexdigest()
md5("lamartin")
```
La valeur renvoyée par `md5` est ici une chaîne de caractères qui doit être interprétée en base 16 (hexadécimal) : par exemple, $a$ correspond à $10$, $b$ à $11$...
MD5 est une **fonction de hachage cryptographique**, ce qui signifie que le nombre de bits d'une empreinte est une constante, indépendant de l'entrée (la taille de $h(x)$ est constante, indépendante de $x$).
**Question** : Combien y a t-il de bits dans un caractère en hexadécimal ?
Sur $k$ bits on peut stocker $2^k$ valeurs différentes. Donc il faut $4$ bits pour avoir $2^4 = 16$ valeurs différentes.
:::{admonition} Exercice 13
:class: note
Combien de bits sont utilisés pour une empreinte MD5 ?
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
len(md5("lamartin"))*4 # on trouve 128 bits
```
---
Pour trouver une collision, on pourra générer des chaînes de caractères aléatoires `s` en stockant dans un dictionnaire la clé `md5(s)` avec la valeur `s`. Si l'empreinte existe déjà dans le dictionnaire, c'est qu'on a trouvé une collision.
On utilisera la fonction suivante génère une chaîne de caractères aléatoire de longueur `n`.
```{code-cell} ipython3
def rdm_str(n):
import string
import random
return ''.join(random.choice(string.ascii_lowercase) for i in range(n))
rdm_str(10) # exemple
```
:::{admonition} Exercice 14
:class: note
Écrire une fonction `find_collision(n, p, k)` qui cherche une collision en générant `n` chaînes de caractères aléatoires de tailles `p`. Pour que la recherche ne prenne pas trop de temps, seuls les `k` premiers caractères de `md5(s)` seront considérés (avec `md5(s)[:k]`). On pourra prendre `k = 9`, `n = 100000`, `p = 10`.
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
def find_collision(n, p, k):
seen = {}
for n in range(n):
s = rdm_str(p)
h = md5(s)[:k]
if h in seen and s != seen[h]:
print(f"{seen[h]} {s} ont le hash " + h)
seen[h] = s
find_collision(1000000, 10, 9)
```
---
### Verification de l'intégrité d'un fichier
Un ami vous propose d'installer la toute dernière version de python qu'il héberge gentillement sur son serveur. Malheureusement vous n'êtes pas certain que cette version soit bien celle d'origine...
Il vous propose deux archives censées contenir toutes les deux la même version de python.
https://raw.githubusercontent.com/tcanta/itc2a/master/payloads/payload1/Python-3.13.0rc2.tgz
https://raw.githubusercontent.com/tcanta/itc2a/master/payloads/payload2/Python-3.13.0rc2.tgz
:::{admonition} Exercice 15
:class: note
Vérifiez l'intégrité de ces fichiers en calculant leurs hashs MD5 respectifs et en les comparant au hash original.
```
ad7f44153649e27ec385e7633e853e03
```
:::
Cette vérification est aujourd'hui insuffisante pour garantir l'intégrité du fichier à cause des problèmes de collision vus plus haut !
Lien vers la page de la release python utilisée:
https://www.python.org/downloads/release/python-3130rc2/
**Remarque** : les tries sont utilisés pour la complétion automatique (proposition de complétion d'un mot en cours d'écriture, par exemple sur téléphone), pour la correction orthographique...
Pour stocker un trie, on utilisera un dictionnaire où chaque clé est l'étiquette d'une arête sortant de la racine et la valeur est le dictionnaire correspondant au fils. Une feuille (sommet sans fils) est représentée par le dictionnaire vide.
Par exemple, le trie contenant l'ensemble de mots $\{$ car, cat, cd, ok $\}$ est représenté par :
```{code-cell} ipython3
trie_ex = {
"c" : {
"a" : {
"r" : { "$" : {} },
"t" : { "$" : {} }
},
"d" : { "$" : {} }
},
"o" : {
"k" : { "$" : {} }
}
}
trie_ex
```
:::{admonition} Exercice 5
:class: note
1. Dessiner le trie contenant les mots art, axe, set.
2. Définir ce trie sous forme d'un dictionnaire.
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
trie = {
"a": {
"r": {
"t": { "$" : {} },
},
"x": {
"e": { "$" : {} },
},
},
"s": {
"e": {
"t": { "$" : {} },
},
},
}
```
---
:::{admonition} Exercice 6
:class: note
Écrire une fonction `trie_size(trie)` pour afficher le nombre de mots appartenant à un trie. Pour cela, on parcourt récursivement le trie en comptant le nombre de $.
:::
```python
def trie_size(trie):
n = 0 # compte le nombre de $
for k in trie:
...
return n
```
```{code-cell} ipython3
:tags: ["hide-cell"]
def trie_size(trie):
n = 0
for k in trie:
if k == '$':
return 1
else:
n += trie_size(trie[k])
return n
```
```{code-cell} ipython3
trie_size(trie_ex)
```
---
:::{admonition} Exercice 7
:class: note
Écrire une fonction `trie_add(trie, m)` pour ajouter un mot `m` dans un trie. On pourra compléter le code ci-dessous.
:::
```python
def trie_add(trie, m):
for c in m: # parcours des lettres c de m
if ...: # s'il n'y a pas d'arête sortante de trie étiquetée par c
... # créer une nouvelle association (c, dictionnaire vide)
trie = trie[c] # descendre dans l'arbre suivant la lettre c
... # ajouter un '$' à la fin
```
```{code-cell} ipython3
:tags: ["hide-cell"]
def trie_add(trie, m):
for c in m:
if c not in trie:
trie[c] = dict()
trie = trie[c]
trie['$'] = dict()
```
```{code-cell} ipython3
trie = {}
trie_add(trie, "arbre")
trie_add(trie, "arete")
trie
```
---
:::{admonition} Exercice 8
:class: note
Écrire une fonction `trie_print(trie)` pour afficher les mots `m` appartenant à un trie. Vérifier avec l'exemple précédent.
On pourra utiliser une fonction auxiliaire récursive `aux(t, m)` qui s'appelle récursivement sur chaque noeud `t` du trie, en conservant les lettres déjà parcourues dans la chaîne de caractères `m`.
:::
```python
def trie_print(trie):
def aux(t, m):
...
aux(trie, "")
```
```{code-cell} ipython3
:tags: ["hide-cell"]
def trie_print(trie):
def aux(t, m):
for k in t:
if k == '$':
print(m)
else:
aux(t[k], m + k)
aux(trie, "")
```
```{code-cell} ipython3
trie_print(trie_ex)
```
---
:::{admonition} Exercice 9
:class: note
Écrire une fonction `trie_has(trie, m)` pour tester si `m` appartient à un trie.
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
def trie_has(trie, mot):
def aux(t, m, i): # t est le sous-arbre, m est le mot recherché, i est l'indice de la lettre courante
if i == len(m):
return '$' in t
if m[i] not in t:
return False
return aux(t[m[i]], m, i + 1)
return aux(trie, mot, 0)
```
```{code-cell} ipython3
print(trie_has(trie_ex, "carte"))
print(trie_has(trie_ex, "car"))
```
---
**Compléments :**
## Fonctions de hachage
De manière informelle, on dit qu'une fonction $h : X \longrightarrow Y$ est une **fonction de hachage** si $X$ est un ensemble de grande taille (généralement infini) et $Y$ est un ensemble fini (souvent un ensemble d'entiers).
L'intérêt d'une fonction de hachage est de transformer un élément "complexe" $x \in X$ (par exemple, une image, un film...) en une empreinte $h(x)$ qui soit plus simple à manipuler et qui utilise moins d'espace mémoire.
Quelques propriétés souhaitables, selon le contexte, sur une fonction de hachage :
- Facilement calculable : pouvoir calculer $h(x)$ en O(1), par exemple.
- Difficile à inverser : étant donné un $y$, il doit être impossible en pratique (c'est-à-dire prendre un temps extrêment long - typiquement une complexité exponentielle) de trouver un $x$ tel que $h(x) = y$.
- Résistance aux collisions : il doit être impossible en pratique de trouver $x, x' \in X$ tels que $h(x) = h(x')$.
Voici quelques applications possibles des fonctions de hachage :
- Table de hachage : c'est une implémentation possible de dictionnaire (voir cours).
- Stockage de mot de passe : au lieu de mémoriser un mot de passe en clair sur un ordinateur ou une base de donnée (qui peut être compromis), on conserve son empreinte par une fonction de hachage.
- Signature numérique : ajout d'une empreinte à un email permettant de garantir l'identité de son expéditeur.
- Checksum : vérifier qu'un fichier a été téléchargé sans erreur, en comparant son empreinte à l'empreinte originale.
### Checksum
Une des applications des fonctions de hachage consiste à vérifier l'intégrité d'un fichier après l'avoir téléchargé (pour détecter d'éventuelles erreurs de transmission). Pour cela, on calcule une empreinte (*checksum*) du fichier téléchargé que l'on compare avec l'empreinte du fichier original.
Dans la suite, nous implémentons un algorithme de checksum très simple (mot de parité) sur une chaîne de caractères.
Dans la suite, on utilisera `ord(c)` qui renvoie le code Unicode d'un caractère `c`.
:::{admonition} Exercice 10
:class: note
Quel est le code Unicode de `a` ? de `z` ?
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
ord('a') # 97
ord('z') # 122
```
---
:::{admonition} Exercice 11
:class: note
Écrire une fonction `code(s)` renvoyant une liste `L` telle que `L[i]` soit le code Unicode de `s[i]`.
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
def code(s):
L = []
for c in s:
L.append(ord(c))
return L
```
```{code-cell} ipython3
code("lamartin")
```
Si $a$ est un entier, on note $a_i$ le $i$ème bit de $a$ en base $2$. Le XOR de deux entiers $x$ et $y$ est un entier $z$ tel que $z_i = 1$ si et seulement si $x_i = 1$ ou $y_i = 1$, mais pas les deux. Par exemple, le XOR de $9 = 1001_2$ et $5 = 0101_2$ est $12 = 1100_2$.
En Python, le XOR est obtenu par `x^y`.
:::{admonition} Exercice 12
:class: note
Sans ordinateur, convertir $11$ et $6$ en base $2$ puis calculer leur XOR. Vérifier ensuite avec Python.
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
def checksum(s):
from functools import reduce
return reduce(lambda x, y: x^y, map(ord, s))
# Est-ce le code le plus clair ? Pas quand on utilise pas les lambda expressions régulièrement...
```
```{code-cell} ipython3
checksum("martin")
```
---
### Recherche de collisions
Une des propriétés désirable sur une fonction de hachage est d'être résistante aux collisions : il doit être très difficile en pratique de trouver $x, x' \in X$ tels que $h(x) = h(x')$. Sinon, il serait possible pour un attaquant d'envoyer un message en lui attribuant une signature d'une autre personne, par exemple.
MD5 est une fonction de hachage célèbre qui n'est plus considérée comme sûre : des collisions MD5 ont notamment été utilisées [par un malware qui a touché l'Iran](https://en.wikipedia.org/wiki/Flame_(malware)).
Dans la suite, nous cherchons des collisions partielles pour MD5.
Voici un exemple d'utilisation de MD5 :
```{code-cell} ipython3
import hashlib
def md5(s):
return hashlib.md5(s.encode("utf-8")).hexdigest()
md5("lamartin")
```
La valeur renvoyée par `md5` est ici une chaîne de caractères qui doit être interprétée en base 16 (hexadécimal) : par exemple, $a$ correspond à $10$, $b$ à $11$...
MD5 est une **fonction de hachage cryptographique**, ce qui signifie que le nombre de bits d'une empreinte est une constante, indépendant de l'entrée (la taille de $h(x)$ est constante, indépendante de $x$).
**Question** : Combien y a t-il de bits dans un caractère en hexadécimal ?
Sur $k$ bits on peut stocker $2^k$ valeurs différentes. Donc il faut $4$ bits pour avoir $2^4 = 16$ valeurs différentes.
:::{admonition} Exercice 13
:class: note
Combien de bits sont utilisés pour une empreinte MD5 ?
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
len(md5("lamartin"))*4 # on trouve 128 bits
```
---
Pour trouver une collision, on pourra générer des chaînes de caractères aléatoires `s` en stockant dans un dictionnaire la clé `md5(s)` avec la valeur `s`. Si l'empreinte existe déjà dans le dictionnaire, c'est qu'on a trouvé une collision.
On utilisera la fonction suivante génère une chaîne de caractères aléatoire de longueur `n`.
```{code-cell} ipython3
def rdm_str(n):
import string
import random
return ''.join(random.choice(string.ascii_lowercase) for i in range(n))
rdm_str(10) # exemple
```
:::{admonition} Exercice 14
:class: note
Écrire une fonction `find_collision(n, p, k)` qui cherche une collision en générant `n` chaînes de caractères aléatoires de tailles `p`. Pour que la recherche ne prenne pas trop de temps, seuls les `k` premiers caractères de `md5(s)` seront considérés (avec `md5(s)[:k]`). On pourra prendre `k = 9`, `n = 100000`, `p = 10`.
:::
```{code-cell} ipython3
:tags: ["hide-cell"]
def find_collision(n, p, k):
seen = {}
for n in range(n):
s = rdm_str(p)
h = md5(s)[:k]
if h in seen and s != seen[h]:
print(f"{seen[h]} {s} ont le hash " + h)
seen[h] = s
find_collision(1000000, 10, 9)
```
---
### Verification de l'intégrité d'un fichier
Un ami vous propose d'installer la toute dernière version de python qu'il héberge gentillement sur son serveur. Malheureusement vous n'êtes pas certain que cette version soit bien celle d'origine...
Il vous propose deux archives censées contenir toutes les deux la même version de python.
https://raw.githubusercontent.com/tcanta/itc2a/master/payloads/payload1/Python-3.13.0rc2.tgz
https://raw.githubusercontent.com/tcanta/itc2a/master/payloads/payload2/Python-3.13.0rc2.tgz
:::{admonition} Exercice 15
:class: note
Vérifiez l'intégrité de ces fichiers en calculant leurs hashs MD5 respectifs et en les comparant au hash original.
```
ad7f44153649e27ec385e7633e853e03
```
:::
Cette vérification est aujourd'hui insuffisante pour garantir l'intégrité du fichier à cause des problèmes de collision vus plus haut !
Lien vers la page de la release python utilisée:
https://www.python.org/downloads/release/python-3130rc2/